Keys to Successful Observability
Seven essential practices for building observable systems from day one.
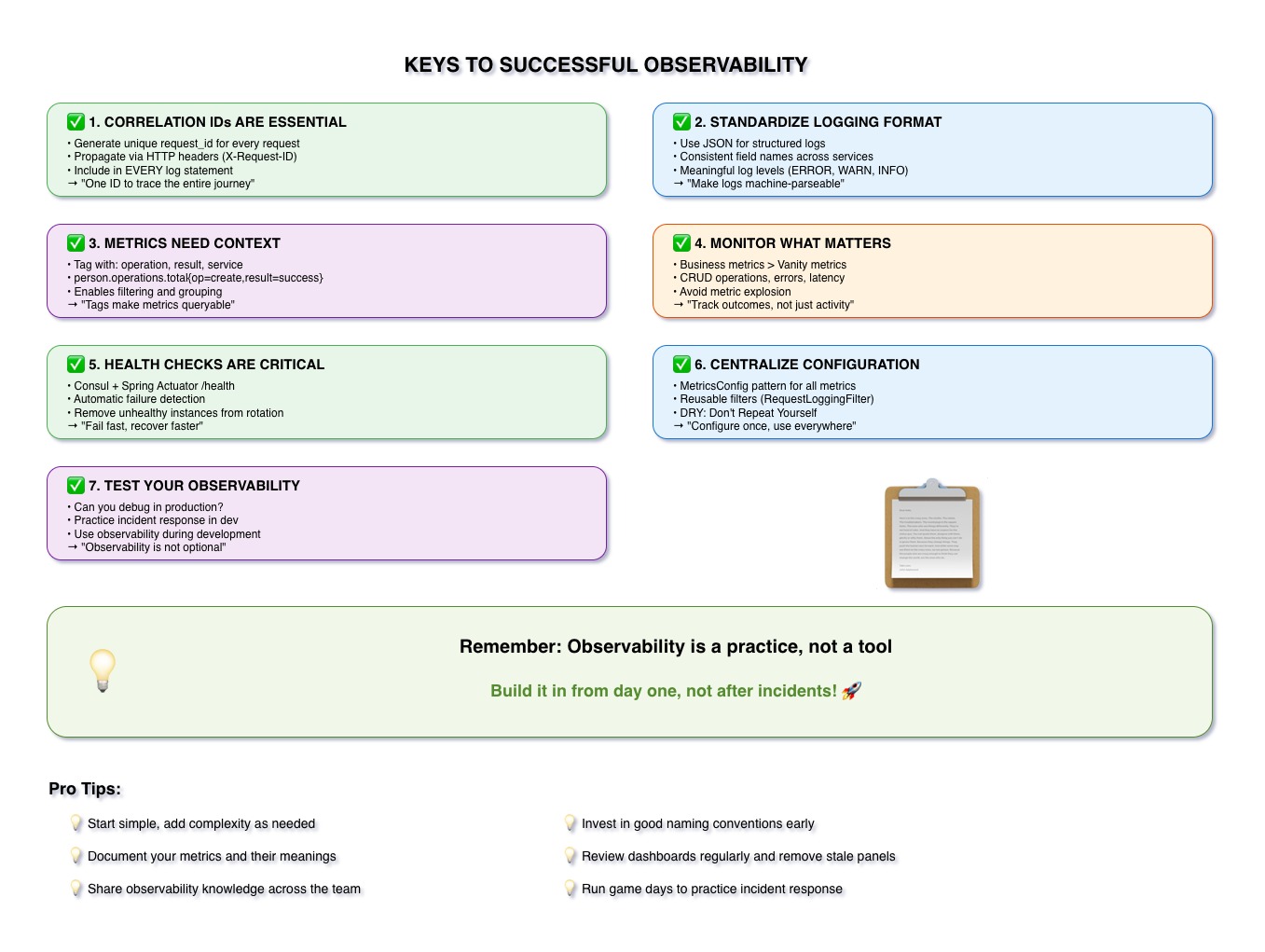
1. Correlation IDs Are Essential
Use request_id everywhere
- Generate unique ID for every request
- Propagate via HTTP headers (X-Request-ID)
- Include in EVERY log statement
- Track entire journey across all services
Why: Without correlation IDs, distributed tracing is impossible
2. Standardize Logging Format
Use JSON logs with consistent field names
- Structured logging (JSON format)
- Consistent field names across all services
- Meaningful log levels (ERROR, WARN, INFO, DEBUG)
- Include context (service name, instance ID, timestamps)
Why: Makes logs machine-parseable and searchable
3. Metrics Need Context
Tag metrics with operation, result, and service name
- Example:
person.operations.total{operation=create, result=success} - Enables filtering and grouping
- Allows complex queries with PromQL
- Makes metrics more useful for debugging
Why: Tags make metrics queryable and actionable
4. Monitor What Matters
Business metrics > Vanity metrics
- Track CRUD operations, errors, latency
- Monitor user-facing metrics (page load time, success rate)
- Avoid metric explosion - focus on what matters
- Track outcomes, not just activity
Why: Too many metrics = noise, not signal
5. Health Checks Are Critical
Integrate Consul + Spring Actuator
- Expose /actuator/health endpoint
- Automatic failure detection via Consul
- Remove unhealthy instances from rotation
- Include database and dependency checks
Why: Fail fast, recover faster
6. Centralize Configuration
Use patterns like MetricsConfig
- Single place for all metrics definitions
- Reusable filters (RequestLoggingFilter)
- DRY: Don't Repeat Yourself
- Easier to maintain and update
Why: Configure once, use everywhere
7. Test Your Observability
Practice during development
- Can you debug in production?
- Practice incident response in dev environment
- Use observability tools during development
- Don't wait for production incidents to test
Why: Observability is not optional
Key Takeaways
- Correlation IDs enable distributed tracing
- Standardization makes logs searchable
- Context-rich metrics enable powerful queries
- Health checks provide automatic failure detection
- Observability is a practice, not just tools
- Build it in from day one